Chapter 1: Some Statistical Practices that Make Sense
Financial systems, such as stock markets, involve a large number of interacting decisions based on many different time-varying levels of knowledge, processing capabilities, motivations and financial resources. Due to this complexity, theories of financial system behavior cannot determine future prices and returns. Said differently, the models termed “financial theories” are actually just working hypotheses generally formed retrospectively (empirically) to fit the past.
Lack of solid theories leaves researchers to explore a jungle of empirical data via statistical inference, constructing samples and looking for past conditions (indicators) that relate strongly to future outcomes (returns) within those samples. Investors then make the leap (despite limitations in empirical research and changes in the market conditions) that future data is enough like past data to apply findings from such inferences to investment decisions.
How should investors generate and interpret research findings in such an environment?
1.1 Significance
Conventions for “statistical significance” in academic research focus on 99%, 95% and 90% levels of confidence in findings for a sample/methodology that is arguably representative of reality. Calculation of confidence levels is straightforward, combining the magnitude of a relationship between predictive input and predicted output variables (for example, between the lagged value of an indicator and a future asset return) with its consistency. Making research representative of reality is not straightforward. For example:
- Samples sometimes contain extreme values of input and output variables that may be recording errors or results of very unusual market conditions (such as negative aggregate earnings in a stock market, making the price-to-earnings ratio negative). Researchers sometimes make extreme data go away by truncating samples or adjusting values.
- Samples may be biased (see Chapter 2) by systematically excluding failed companies or discontinued funds (survivorship bias) such that the residual samples are unrepresentative of future samples.
- Many researchers employ optimization (or at least iteration) to discover and amplify potentially useful relationships. This snooping for significance tends to make findings sample-specific, and thereby unrepresentative of future samples. Snooped findings tend to overstate future performance expectations (see Chapter 3).
- Market models may include dubious general assumptions about reality, such as:
- Many researchers assume that market variables are very “tame” (have normal distributions). Evidence indicates that financial asset returns exhibit to varying degrees “wild” power law distributions. This wildness disrupts assumptions made in interpreting simple statistics, including mean (average) and standard deviation, and therefore derived statistics used to assess investment performance such as Sharpe ratio. For very wild distributions, one new observation can change simple statistics so much that they are not useful for prediction.
- Many researchers ignore the effects of investment frictions (transaction fees, bid-ask spreads, impacts of trading, costs of shorting, costs of leverage…). Findings based on net returns may differ materially from those based on gross returns (see Chapter 4).
- Many researchers ignore the likelihood that markets adapt. Investors learn from research and experience and change behaviors accordingly, making future samples inherently different from past samples (see Chapter 5).
Some or all of these disruptions of the connection between the retrievable past and the exploitable future find their way into all research. Investors must make decisions with less confidence (probably much less confidence) than reported in studies, to a substantial degree guessing which edges from research are good enough to warrant taking a risk.
The following sections describe some practices that reduce the chance of acting on poor edges.
1.2 Sample Duration
Finding a practically reliable investing edge via inference from backtests requires a combination of low variability (randomness) in observations and large sample size. A large sample size means long sample duration. How long is long?
In general, asset returns exhibit substantial randomness. The sample period for a backtest should therefore be the longer of:
- Many times as long as the measurement frequency of any input variable (indicator). For example, if an investor uses an indicator measured daily to predict future returns, the sample should be many days in length. If an investor uses an indicator measured monthly or annually, the sample should be many months or years.
- Many times as long as the measurement interval for any indicator. For example, if an investor uses a 200-day simple moving average as an indicator, the sample period should be many multiples of 200 (market) days to span many indicator environments. If the indicator is stage of the business cycle, then the sample should span many business cycles.
- Many times as long as the measurement interval for resulting returns. For example, if an investor measures annual returns, the sample should be many years long.
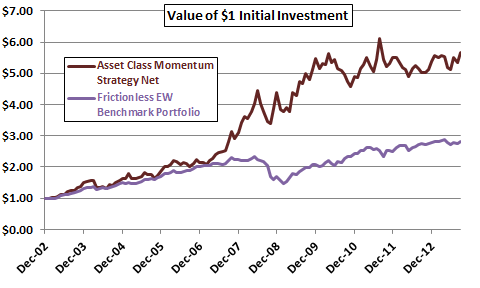
Figure 1-2a illustrates some sample duration issues. It shows the cumulative value of $1 initial investments from the end of December 2002 through September 2013 (130 months) in:
- A simple asset class momentum strategy presented at CXOadvisory.com. This strategy shifts each month to the one of nine asset class proxies with the highest total return over the past five months. Most of the proxies are exchange-traded funds (ETF).
- An equally weighted and monthly rebalanced portfolio of the nine asset class proxies as a benchmark (conservatively calculated with no rebalancing frictions).
How long a sample is needed to assess reliability? The measurement frequency for the momentum indicators is monthly, so the sample should be many months long (130 months is usually many for practical analysis). However, the momentum measurement interval is five months. The overlap of measurement intervals used for consecutive monthly calculations makes them sticky (introduces autocorrelation in the asset class momentum series). This autocorrelation distorts simple statistical reliability testing. A conservative approach to mitigating this distortion is to consider the sample size to be about 26 independent five-month intervals (not many).
However, visual inspection of the return trajectories suggests that the momentum strategy’s outperformance relative to the benchmark concentrates during the 2008 financial crisis and associated equity bear market. Will the strategy similarly outperform during future bear markets? The sample is extremely small in terms of number of bear markets (one), and most of the ETFs did not exist during prior equity bear markets. It may be practically impossible to construct samples that are long compared to all possible influences.
Figure 1-2a: Performance of an Asset Class Momentum Strategy
Figures 1-2b and 1-2c illustrate issues associated with reversion-to-mean strategies for widely cited indicators that move slowly and vary widely, thereby requiring very long samples.
Figure 1-2b shows the evolution of Robert Shiller’s P/E10, the ratio of inflation-adjusted U.S. stock index level averaged over a month to inflation-adjusted aggregate market earnings averaged over the past ten years, during January 1881 through September 2013. Data are from Robert Shiller’s Online Data. P/E10 ranges from 4.8 to 44.2 over this period. The figure also shows the overall series average (dashed line, the historical mean viewed retrospectively) and the inception-to-date (ITD) average (thin double line, the historical mean experienced in real time) over the sample period. It is arguable that this sample is not long enough to determine a stable mean, one to which the indicator reliably reverts. A value-seeking investor who holds stocks only when P/E10 is below its ITD average sells in late 1988 and remains out of stocks until late 2008 (about 20 years). During that time, after more than a century of data, the ITD average rises from 14.6 to 16.3. After holding stocks for seven months, the investor then exits again. Since late 1988, the investor would have been in stocks 2% of the time. These findings undermine belief in a stable mean to which P/E10 reliably reverts within a generation. In other words, an investor would need a much longer sample to determine a stable mean (many times the 10-year measurement interval of the average earnings input), and a very long investment horizon to exploit reversion to it.
Figure 1-2b: P/E10 with Inception-to-Date and Total Series Averages
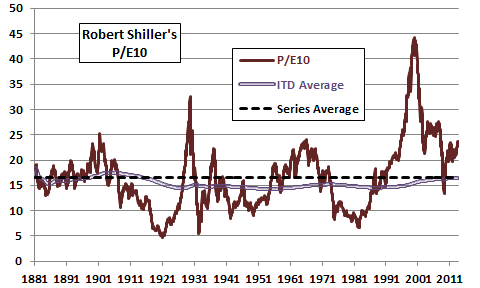
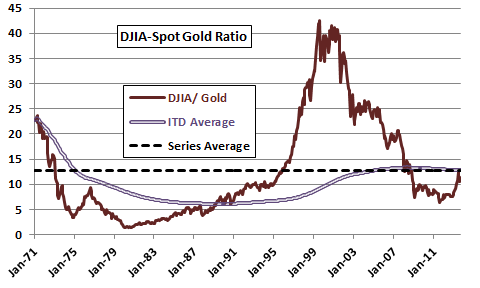
Figure 1-2c shows the evolution of the ratio of the Dow Jones Industrial Average (DJIA) to the spot price of gold in U.S. dollars during January 1971 (soon after gold began freely trading in the U.S.) through September 2013. Data are from the Federal Reserve Bank of St. Louis’ Federal Reserve Economic Data (FRED) for both DJIA and spot gold price. The ratio ranges from 1.3 to 42.5 over this period. The figure also shows the overall series average (dashed line, the historical mean viewed retrospectively) and the inception-to-date (ITD) average (thin double line, the historical mean experienced in real time) over the sample period. The ITD average rises from 6.1 in the late 1980s to over 13 in the late 2000s. This variation indicates that an investor would need a much longer sample to determine a stable mean, and a very long investment horizon to exploit reversion.
Figure 1-2c: DJIA-Gold Ratio with Inception-to-Date and Total Series Averages
Working against collection of very long samples are two concerns:
- The quality of old data is suspect due to potentially loose recording practices or an immature (thinly traded and materially inefficient) market.
- Old data may be otherwise inapplicable to current conditions. Changes in economic and monetary environments, regulations for investors and companies, tax levels and trading technology plausibly change financial markets such that indicator-future return relationships change over time.
More fundamentally confounding to sample-building is financial market adaptation (see Chapter 5), with indicator-future return relationships changing continuously as investor knowledge evolves.
As observed in the above discussion, the investment horizon required to exploit an indicator increases with the sample duration required to test indicator reliability. A long investment horizon is susceptible to the same concerns about changes in financial markets as a long backtest sample.
1.3 Measurement Intervals
A measurement interval is the time between the first and last measurements used to construct an input variable (indicator) or an output variable (return). For example, the Bureau of Labor Statistics uses a measurement interval of 12 months for the U.S. inflation rate, based on the change in the Consumer Price Index (CPI) between the current month and 12 months ago. This 12-month measurement interval is distinct from the measurement frequency, which is monthly. Many other economic indicators have a 12-month measurement interval, but the government sometimes performs standalone quarterly measurements. Companies also measure firm performance on annual cycles but generally perform standalone quarterly measurements.
When the measurement frequency is shorter than the measurement interval, investors can create a variable to compress the measurement interval to the measurement frequency. For example the month-to-month change in CPI is a monthly inflation rate with a one-month measurement interval. Such compressions shorten the sample duration needed to span many measurement intervals, but they also generally produce much noisier data (random fluctuations are a larger fraction of measurements). The noisier the data, the longer the sample duration needed to extract a signal.
Financial markets themselves make daily, weekly and monthly measurement intervals easy to use. Investors have considerable latitude to use these intervals, or multiples of them, in constructing technical indicators (such as moving averages and relative performance indicators).
When there is latitude to set the measurement interval, investors often use empirical data to determine which interval works best (and thereby incorporate snooping bias as discussed in Chapter 3). For example, the simple asset class momentum strategy from Figure 1-1 employs a five-month historical return interval to rank nine asset class proxies and pick the one with the strongest momentum. Figure 1-3a summarizes findings of an investigation of the optimal ranking interval for this strategy over the available sample period. This investigation compares terminal values of $1.00 initial investments in the strategy at the end of July 2003 based on different ranking intervals ranging from one month to 12 months, with a 0.25% switching friction applied whenever the strategy signals a change in holdings. Short ranking intervals mostly work better than long intervals, and a five-month ranking interval is optimal. Using average net monthly return rather than net terminal value points to the same optimal ranking interval. Ranking intervals of four months and six months are also attractive compared to shorter and longer ones.
Figure 1-3a Optimal Ranking Interval for Simple Asset Class Momentum Strategy
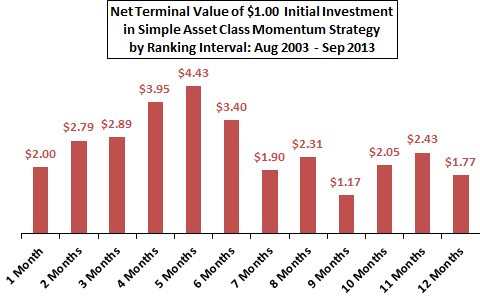
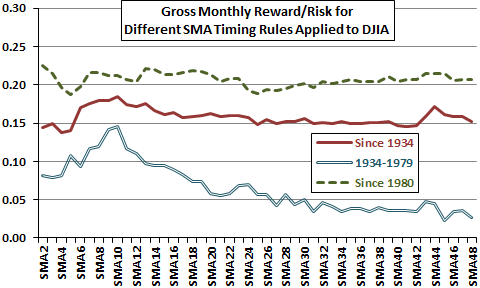
Figure 1-3b summarizes findings of an investigation of the optimal measurement interval for a long-term simple moving average (SMA) as applied to timing the Dow Jones Industrial Average (DJIA). This investigation measures the gross monthly reward-risk ratio (average gross monthly return divided by standard deviation of monthly returns) for holding DJIA when the index trades above its SMA at the prior monthly close and cash when the index trades below its SMA at the prior monthly close. Data are from FRED. This analysis considers SMAs ranging from two months (SMA2) to 48 months (SMA48) but ignores trading frictions for index-cash switches, return on cash and dividends, which could differ across SMAs and affect findings. The investigation considers an overall sample period of January 1934 through September 2013 and two subperiods: January 1934 through December 1979, and January 1980 through September 2013.
Results indicate that SMA10 is optimal during the early subperiod and therefore slightly for the overall sample period. However, SMA10 is not optimal in the later subperiod, during which there is no clear winner. Inconsistencies across subperiods suggest that luck plays a role in historical optimality (further discussion in Chapter 3).
Figure 1-3b: Optimal SMA Measurement Interval for Timing DJIA
1.4 Indicator and Return Measurement Frequency
As described above, indicator measurement frequency is different from indicator measurement interval. For example, investors typically iterate long-term SMA measurements at least monthly, and sometimes weekly or daily. These frequent checks involve measurement intervals that overlap.
For many indicators, investors cannot choose the measurement frequency. For example, the Bureau of Labor Statistics sets the measurement frequency at one month for the U.S. inflation rate. The government sets the measurement frequency for many other economic indicators, focusing on monthly and quarterly.
Financial markets themselves make daily, weekly and monthly measurement frequencies easy to use, and investors have considerable latitude to set the measurement frequency in multiples of these units when constructing technical indicators.
It is plausible that predictable price changes are market responses to new information, and the return measurement frequency should match the indicator measurement frequency (the arrival rate of new information). It is also plausible that price responds most strongly to new information immediately after its availability, with response fading over time (even before the next increment of new information is available). By this logic, a return measurement frequency less than the indicator measurement frequency may support profitable trading.
However, the noise-to-signal ratio is generally higher for high-frequency than low-frequency measurements, so increasing the measurement frequency to exploit new information tends to increase the number of spurious signals (random fluctuations become large compared to signal strength). More spurious signals mean more trading and greater cumulative investment frictions.
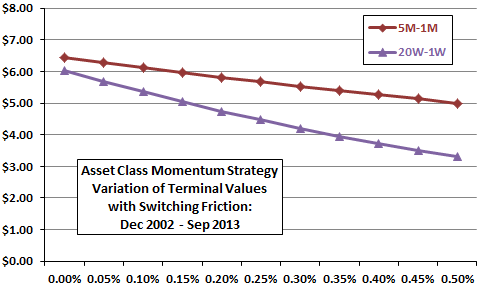
For example, Figure 1-4a returns to the simple asset class momentum strategy introduced in Figure 1-1 for a comparison of monthly versus weekly measurement frequencies. The monthly version shifts each month to the one of nine asset class proxies with the highest total return over the past five months (5M-1M). The weekly version shifts each week to the one of nine asset class proxies with the highest total return over the past 20 weeks (20W-1W), which is about five months. The compared outcomes are terminal values as of the end of September 2013 of $1.00 initial investments near the end of December 2002, with a range of switching frictions (from 0.00% to 0.50%) applied whenever a strategy signals a change in holdings. This range of frictions is reasonable for the sample period and the type of assets traded. Over the sample period, the 20W-1W strategy generates 121 asset switches compared to just 51 for the 5M-1M strategy.
Results in this case do not support belief that more frequent measurement of asset momentum extracts incremental useful information from asset prices—the 5M-1M strategy marginally outperforms the 20W-1W strategy with no switching frictions. Also, because the 20W-1W strategy generates more than twice the number of switches as the 5M-1M strategy, the former degrades more quickly as switching friction increases. In, other words, the gap between terminal values for monthly and weekly measurement frequencies widens as asset switching friction increases from 0.00% to 0.50%.
For this type of strategy and sample period, the slower measurement frequency works better than the faster one.
Figure 1-4a: Effects of Varying Measurement Frequency on Simple Asset Class Momentum Strategy
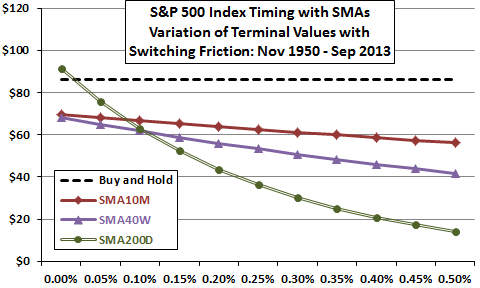
As an additional example, consider three long-term SMAs of approximately the same length: a 10-month SMA measured monthly (SMA10M); a 40-week SMA measured weekly (SMA40W); and, a 200-day SMA measured daily (SMA200D). For each variation, the strategy holds the S&P 500 Index when the index is above the SMA at the last measurement and cash when the index is below, with a range of switching frictions (from 0.00% to 0.50%) applied whenever a strategy signals a change in holdings. This range of frictions is low compared to actual costs of trading for much of the sample period. Over the sample period, the SMA200D strategy generates 370 switches, compared to 182 for the SMA40W strategy and 88 for the SMA10M strategy.
The analysis ignores return on cash and dividends, which likely differs little across SMAs since all spend about the same percentage of time in stocks (69%). However, ignoring return on cash puts the SMA rules at a disadvantage compared to buying and holding the index (Buy and Hold), and ignoring dividends puts Buy and Hold at a disadvantage compared to the SMA rules.
Results indicate that SMA200D outperforms both SMA40W and SMA10M for very low levels of switching friction, extracting incremental information from prices by measuring more frequently. SMA200D even beats Buy and Hold for the frictionless scenario. SMA40W does not extract incremental information from prices compared to SMA10M.
Because of its relatively large number of trades, the performance of SMA200D degrades rapidly as switching friction increases. The performance of SMA40W degrades less rapidly than that of SMA200D but more rapidly than that of SMA10M. For this general strategy and sample period, the slower measurement frequency works better than the faster alternatives after accounting for investment frictions.
Figure 1-4b: Effects of Varying Measurement Frequency on Timing the S&P 500 Index with SMAs
The preceding examples suggest that trading frictions may be the number one consideration in choosing a measurement frequency for many investors.
1.5 Other Considerations
Some studies introduce overlapping indicator and/or return measurement intervals by incorporating new information in time increments shorter than the complete measurement interval. For example:
- Measuring a 10-month simple moving average each month involves consecutive 10-month measurement intervals overlapping by 90%.
- Maintaining a rolling one-year correlation of weekly returns for two assets involves consecutive 52-week measurement intervals overlapping by 98%.
- Projecting five-year returns each year involves consecutive 5-year forecast intervals overlapping by 80%.
- Forecasting an annual inflation rate monthly involves consecutive 12-month forecast intervals overlapping by 92%
The motivation for introducing such overlaps is to put new information to use quickly within models that use relatively long measurement intervals. However, continual reuse of information via overlapping intervals makes consecutive observations interdependent. Commonly used statistical tests assume that observations are independent, and applying such tests to interdependent data may exaggerate the reliability of relationships between indicators and returns. Similarly, an investor may believe that a large number of overlapping observations means reliable inference, while the number of independent observations is small. There are complex statistical methods to correct the bias in interdependent data (look for the Newey-West correction method). A simple mitigation for the bias is to winnow data to remove overlaps (thereby reducing sample size). For example, winnowing the P/E10 data used in Figure 1-2a means selecting one observation from each decade, such that earnings for a given year are not reused in any two observations. Winnowing several times after shifting the starting point by a year and then averaging results mitigates loss of data.
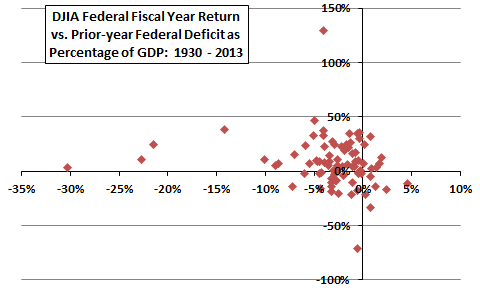
Some studies exclude unusual data as “outliers” because of suspected miscalculation or misreporting, or because the researcher judges associated circumstances to have negligible likelihood of recurrence. For example, Figure 1-5 is a scatter plot depicting the relationship between annual Dow Jones Industrial Average (DJIA) returns for U.S. federal government fiscal years versus prior-year federal deficits as a percentage of U.S. Gross Domestic Product (GDP). DJIA levels are from FRED, and federal deficit data are from the Office of Management and Budget. The four observations at the extreme left are 1942-1945, encompassing World War II. The extreme observations at the bottom and top are 1932 and 1933, respectively. An investor attempting to predict future stock market returns based on current and projected federal deficits might consider excluding these observations as highly implausible scenarios for future years. A way to mitigate the risk of excluding such observations is to construct forecasts with and without the outliers.
Figure 1-5: DJIA Return vs. Prior-year U.S. Federal Deficit as Percentage of GDP
Using data from the entire sample period to optimize strategy rules and parameters (called in-sample optimization, data snooping and benefit of hindsight) can misleadingly generate very attractive returns within that sample. This issue is so pervasive and material in investment research that it merits an entire chapter (Chapter 3).
1.6 Summary
Key messages from this chapter are:
- Investing edges are much smaller than those implied by the confidence levels expressed in research, because there are so many ways for complex systems to confound the modeling and measuring processes of inference.
- Sound investment strategy testing requires understanding how sample size, measurement interval and measurement frequency interrelate, and how they each relate to input information arrival rate and strategy implementation constraints.
- Charlatans who want to sell apparently sophisticated “sure things” (aka “holy grails”) should jump ahead to Chapter 3 for snooping advice and Chapter 4 for advice on going frictionless, generate some 99% confidence levels and market to investors who have not made it through Chapter 1.
Next, Chapter 2 describes a framework for applying the above concepts logically.