Chapter 3: Avoiding or Mitigating Snooping Bias
Snooping bias, also called mining bias and more loosely benefit of hindsight, is a notorious artificial booster of backtest performance. It takes multiple forms:
- Picking the best of many rules/indicators (strategies, models) for a given data sample
- Optimizing rule parameters for a given data sample
- Restricting a data sample to find favorable performance of a given rule
- Running an investment contest among many individuals
A sentiment shared among researchers in stochastic fields is: “If you torture the data long enough, it will confess to anything.” Because returns are noisy (substantially random), trying many combinations of rules, parameter settings and data samples will generate strategies that outperform benchmarks by extreme good luck. A prosecutor (an investor) satisfied with false confessions is likely to lose in court (the market).
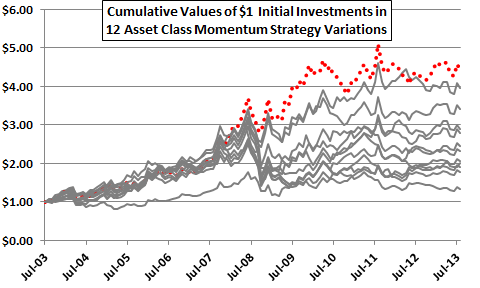
To illustrate, Figure 3-0 depicts the net cumulative values of $1.00 initial investments in each of 12 variations of the simple asset class momentum strategy introduced in Figure 1-1. This strategy shifts each month to the one of nine asset class proxies with the highest total return over a past return measurement (ranking) interval. Most of the proxies are exchange-traded funds (ETF). The 12 variations differ by the length of the ranking interval, from one to 12 months. All variations impose a switching friction of 0.25% whenever the strategy switches funds.
Does the top-performing variation (dotted line) represent a premium earned by extracting truly valuable information from market prices, or just the payout from being the lucky winner of a lottery? The following sections address this question.
Figure 3-0: Performance of 12 Asset Class Momentum Strategy Variations
3.1 Sources of Snooping Bias
Computer hardware, software and networking technology enable rapid construction and exhaustive testing of increasingly complex investment strategy alternatives. Noise (randomness) within a given historical sample of input (indicator) values and output returns will make alternatives perform differently, regardless of any differences in true predictive power of the indicator. More complex strategies offer more alternatives for testing. More test iterations mean greater chance of compounding lucky steps to create a very lucky outcome. More randomness (exhibited as volatility) means more/bigger lucky steps to compound.
Figures 3-1a and 3-1b illustrate the effect of more test iterations. Both charts track cumulative values of “strategies” based on $1.00 initial investments allocated each month to either dividend-adjusted SPDR S&P 500 (SPY) or 13-week U.S. Treasury bills (T-bills). Allocation decisions come from 20 distinct sets of 120 monthly signals to hold T-bills or hold SPY during October 2003 through September 2013 (ten years). Data for SPY and T-bill yields are from Yahoo!Finance. Signals come from a random number generator that produces a value greater than or equal to zero and less than one. If the value for a month is less than 0.5, the “strategies” hold T-bills that month. If the value for a month is greater than or equal to 0.5, the “strategies” hold SPY that month. These “strategies,” bear a switching friction of 0.125% for a change in holdings (but dividend reinvestment is frictionless).
Figure 3-1a shows net cumulative performances for the first five “strategies” and for buying and holding SPY (dotted line). Even though these “strategies” have no intelligence, average monthly returns range from 0.13% to 0.45%, compared to 0.49% for buying and holding SPY. Reward-risk ratios (average monthly return divided by standard deviation of monthly returns) range from 0.05 to 0.15, compared to 0.16 for buying and holding SPY. Terminal values range from $1.12 to $1.62, compared to $2.06 for buying and holding SPY. The “strategies” tend to “make money” because both input series (SPY and T-bills) are profitable over the sample period.
Figure 3-1a: Five “Strategies” that Randomly Pick Either SPY or T-bill Returns Each Month
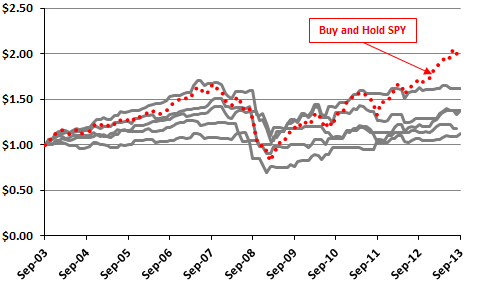
Figure 3-1b shows results for all 20 sets of random monthly signals and for buying and holding SPY (dotted line). Including all 20 “strategies” widens the ranges of average monthly returns (now 0.04% to 0.69%), reward-risk ratios (0.01 to 0.22) and terminal values (now $0.98 to $2.14). The best of the 20 strategies generates a compound annual return of 7.9%, slightly better than the 7.5% for buying and holding SPY. Again, the “strategies” mostly “make money” because both SPY and T-bills are profitable over the sample period.
Figure 3-1b: 20 “Strategies” that Randomly Pick Either SPY or T-bill Returns Each Month
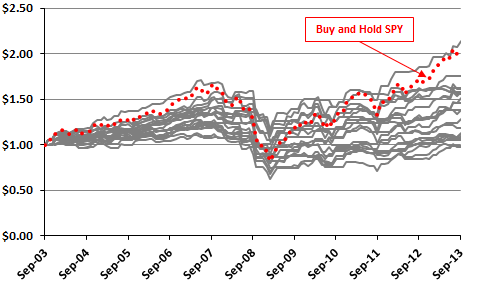
A separate test using 100 sets of random signals (not shown) generates a maximum terminal value of $2.44 (compound annual return 9.4%) via dumb luck. More test iterations means a greater chance of luck compounded into the best and worst results, confounding discovery of truly intelligent strategies.
Small samples and volatile returns amplify snooping bias. A short lucky streak is more likely than a long one, so a lucky streak is more likely to dominate a short sample. And, if a strategy luckily captures a few big upsides and misses big downsides in a short and volatile sample, the compound effect can be dumbly outstanding.
There are statistical methods to estimate this simple kind of snooping bias. However, there is another pervasive aspect of snooping bias that is not practically correctible.
3.2 Second-hand Snooping
There are millions of interconnected researchers exploring an ever increasing number of models, parameter settings and intersecting samples worldwide. This community continuously shares “successful” strategies via published research, research services, advisory services and informal groups. However, this sharing generally does not include reporting and correcting for all model, parameter and sample alternatives considered and discarded in the process of discovering success. It seems likely that participants do not even keep track of the number of alternatives they test. After all, who wants to hear about what does not work?
So investor B adopts a successful strategy from investor A (who considered an unknown number of alternatives in discovering the successful one).Investor B explores a number of alternatives to refine and improve the strategy. Investor C adopts the refined strategy from investor B without knowing how many alternatives investors A and B considered. This process repeated millions of times grows the iceberg below the water line, an aggregate unquantified mass of snooping bias.
Advances in information technology accelerate growth in aggregate second-hand snooping. Investors should arguably exercise escalating due diligence in developing and choosing strategies to implement.
3.3 Defenses against Snooping Bias
There are defenses against snooping bias ranging from simple but time-consuming, to difficult and uncertain, to impractical.
One straightforward defense is to conduct a live “paper” trial of a backtest-winning strategy to see whether it performs as well on completely new data as it does in an historical sample. Such a test generally requires considerable time (patience and potential opportunity loss). Snooping bias is not the only explanation for reduced performance during a live test, but it is a possible explanation. Any tweaking of the strategy or data specification during the live test in response to new data (re-)introduces snooping bias.
Some studies use only part of an historical set of data (the in-sample part) to optimize (train) the strategy and reserve the rest of the data set (the out-of-sample or hold-out part) for unbiased testing. This approach can extend to specifying multiple training and hold-out sets, and reusing training sets as hold-out sets and vice versa for robustness. However, hold-out sets are not live, and any reuse of hold-out sets for multiple strategies contaminates its “freshness” (introduces luck). Also, small samples result in even smaller training and hold-out sets.
Some studies employ contemporaneous data from other markets (for example, other countries) as “fresh” fodder for out-of-sample testing. However, markets often exhibit interdependence (substantial correlation of returns), limiting their capacity to mitigate snooping bias.
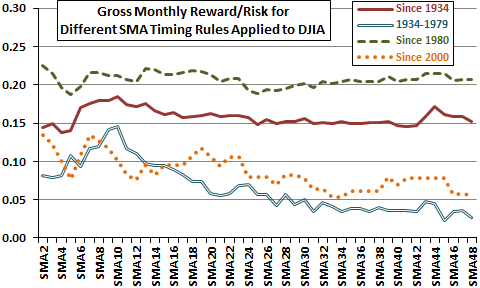
Many studies check consistency of strategy performance across subperiods to ensure that a “lucky” subperiod does not drive overall results (and to ensure the strategy still works with recent data). Figure 3-3a revisits the investigation introduced in Figure 1-3b of the optimal measurement interval for a long-term simple moving average (SMA) as applied to timing the Dow Jones Industrial Average (DJIA). The investigation measures the gross monthly reward-risk ratio (average gross monthly return divided by standard deviation of monthly returns) for holding DJIA when the index trades above its SMA at the prior monthly close and cash when the index trades below its SMA at the prior monthly close. SMAs range from two months (SMA2) to 48 months (SMA48). Testing ignores trading frictions for index-cash switches, return on cash and dividends, each of which could differ across SMAs and affect findings. The investigation considers an overall sample period of January 1934 through September 2013 and three subperiods: January 1934 through December 1979; January 1980 through September 2013; and, January 2000 through September 2013.
SMA10 is barely optimal for the overall sample period. It is only clearly optimal for the early subperiod. It is not optimal for either recent subperiod. Because subsamples are not very long relative to the SMA10 measurement interval, it is plausible that luck drives SMA10 optimality during the early subperiod (but market adaptation is also plausible as discussed in Chapter 5).
Subperiod comparison, like in-sample/out-of-sample testing, requires long overall sample periods so that subperiods support reasonably reliable inference.
Figure 3-3a: Snooping SMA10
Some studies gauge the degree of luck in an optimal parameter setting by measuring variation in outcomes across a range of parameter values. If variation is unsystematic and sharp, luck is likely. A reasonably wide range of near-optimal settings suggests some underlying reason for outperformance.
Figure 3-3b illustrates this approach for the past return measurement (ranking) interval of the simple asset class momentum strategy of Figures 1-1 and 3-0. This strategy shifts each month to the one of nine asset class proxies with the highest total return over the ranking interval. Most of the proxies are exchange-traded funds (ETF). Figure 3-3b summarizes average monthly net returns (switching friction 0.25%) for 12 strategy alternatives generated by varying the ranking interval from one to 12 months, denoted on the horizontal axis. Somewhat systematic results suggest that shorter, but not too short, ranking intervals extract some real information from market prices.
Figure 3-3b: Effect of Varying the Ranking Interval for an Asset Class Momentum Strategy
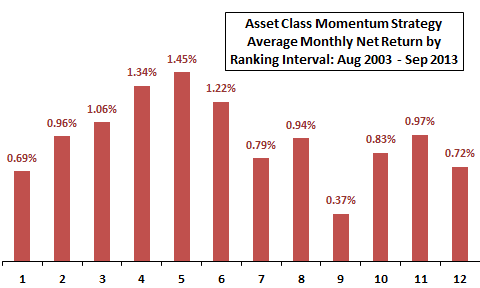
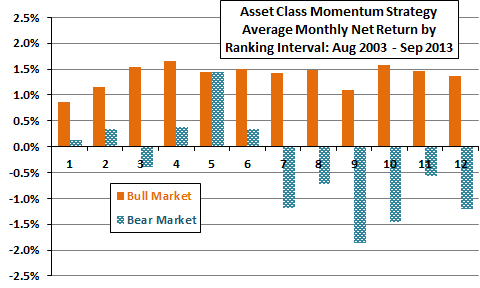
Figure 3-3c goes deeper, summarizing average monthly net returns for the 12 strategy alternatives during U.S. stock market bull and bear regimes, operationally defined as times when the S&P 500 Index is above or below its 10-month SMA at the end of the prior month. These results suggest that the shorter ranking intervals generally offer equity market crash protection, while longer ranking intervals do not. However, the sharp outperformance of the five-month ranking interval during bear regimes suggests luck for that parameter setting.
A short-coming of this assessment is that the sample period is modest relative to the long ranking intervals. Bull and (especially) bear subsamples are even smaller. The combination of sharp difference and very small bear subsample elevates the likelihood that the five-month ranking interval is lucky compared to adjacent ranking intervals. Lucky does not mean that the five-month ranking interval is not optimal, but that its historical outperformance likely overstates its future performance.
Figure 3-3c: Effect of Varying the Ranking Interval for an Asset Class Momentum Strategy
during Equity Bull and Bear Regimes
There are statistical methods to adjust (approximately) for snooping bias based on the time series performance of all snooping trials. Studies generally do not apply such methods, which require discipline in recording all trials and manipulation of very large amounts of data (and cannot account for second-hand snooping).
Some studies use randomization and simulation methodologies (bootstrapping and Monte Carlo testing) to detect snooping bias. From the perspective of most investors, these methods are complex and time-consuming, involving specialized software, very large amounts of data (time series performance or time series signals for all strategies tested), careful setup and intense computation. While these methodologies allow use of an entire sample for testing (no hold-out subsample), the randomization process may disrupt real patterns in the actual time series of returns.
A very simple randomization/simulation check is to compare a selected strategy with many simulations that randomly replace its signals. For example, suppose an investor has selected a U.S. stock market timing strategy that each month signals a position in SPY or T-bills. If that strategy does not perform above or among the best “strategies” shown in Figure 3-1b, then luck is plausible explanation for its performance. If the investor discovered the strategy as the winner among 20 variations, then a genuinely outperforming winner should consistently perform well above the 20 randomly generated “strategies.”
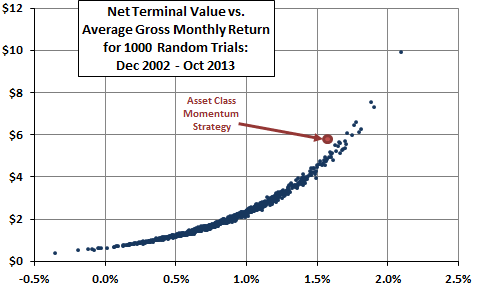
Figure 3-3d illustrates a more complex randomization/simulation check of the of the simple asset class momentum strategy of Figures 1-1, 3-0, 3-3b and 3-3c. The figure relates net terminal value of a $1 initial investment to average gross monthly return for the momentum strategy and for 1,000 trials of a competing “strategy” that allocates all funds each month to one of the nine assets picked at random. The assumed level of switching friction is 0.25%. The momentum strategy outperforms 980 (98%) of the random trials based on average gross monthly return and 991 (99.1%) of random trials based on net terminal value. The momentum strategy falls to the left of the curve for the random trials because it switches its allocation less than half as frequently as the random trials on average. The relatively strong performance of the momentum strategy indicates that it extracts useful information from relative ETF price behaviors.
Figure 3-3d: Asset Class Momentum Strategy vs. Random Asset Selection
Finally, an investor may simply mitigate the fact that snooping bias is pervasive by setting high benchmarks for strategy selection. For example, an investor may simply assume the Sharpe ratio of a newly tested strategy is actually half the calculated value. Some research suggests such a discount is too small for strategies exhibiting marginally attractive Sharpe ratios and too big for those exhibiting very high Sharpe ratios. In other words, snooping bias interpreted via Sharpe ratio is likely smaller percentage-wise for extremely attractive strategies than for marginal strategies.
3.4 Summary
Key messages from this chapter are:
- Investors should routinely subject investment strategies to robustness (stress) tests to detect snooping bias. In other words, investors should always try to break their strategies before their strategies can break them.
- Even when strategies survive robustness tests, investors should assume that all “successful” strategies impound some degree of snooping bias and employ defenses accordingly. Short samples with volatile assets merit extra skepticism.
- Charlatans who want to sell “hot” strategies should test a very volatile asset (maybe equity options) exhaustively to isolate the best-performing rule, parameter settings and sample start date to generate astounding in-sample returns, and market it to investors who did not read this chapter. And, switch to the next hot strategy frequently to avoid the tell of out-of-sample performance.
Next, Chapter 4 addresses the other pervasive weakness of investment strategy research, treatment of investment frictions.