How should researchers address the issue of aggregate/cumulative data snooping bias, which derives from many researchers exploring approximately the same data over time? In the October 2014 version of their paper entitled “. . . and the Cross-Section of Expected Returns”, Campbell Harvey, Yan Liu and Heqing Zhu examine this issue with respect to studies that discover factors explaining differences in future returns among U.S. stocks. They argue that aggregate/cumulative data snooping bias makes conventional statistical significance cutoffs (for example, a t-statistic of at least 2.0) too low. Researchers should view their respective analyses not as independent single tests, but rather as one of many within a multiple hypothesis testing framework. Such a framework raises the bar for significance according to the number of hypotheses tested, and the authors give guidance on how high the bar should be. They acknowledge that they considered only top journals and relative few working papers in discovering factors and do not (cannot) count past tests of factors falling short of conventional significance levels (and consequently not published). Using a body of 313 published and 63 near-published (working papers) encompassing 316 factors explaining the cross-section of future U.S. stock returns from the mid-1960s through 2012, they find that:
- The discovery rate of factors explaining stock returns published in top journals accelerates from about one per year during 1980-1991 to three per year during 1991-2003 to 18 per year during 2004-2012.
- The overwhelming majority of the 316 factors in published and working papers exhibit statistical significance at the 5% level (p-value less than 0.05).
- Given this extensive aggregate/cumulative data snooping, there are many false positives in factor research findings. Researchers should now require a newly discovered factor to have a t-statistic above 3.0, corresponding to a p-value less than 0.0027 (see the chart below).
- Of the 296 published “significant” factors, roughly a third to a half are likely not significant depending on the method used to correct for snooping bias.
- Among prominent factors, book-to-market ratio, momentum, durable consumption goods, short-run volatility and market beta are robust to all methods of adjustment for snooping bias. Earnings-price ratio, liquidity and idiosyncratic volatility are robust to some methods. Market capitalization (size) and default likelihood and are not robust.
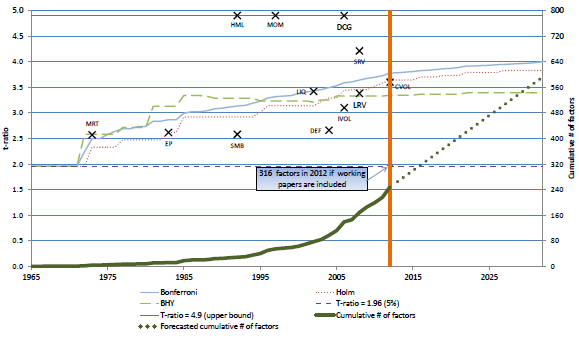
The following figure, taken from the paper, depicts:
- The cumulative number of formally published factors explaining the cross-section of future U.S. stock returns (solid green line and right-hand vertical axis), with a linear extrapolation into the future (dotted green line).
- Via dark crosses, the time of discovery (horizontal axis) and t-statistic (t-ratio, left-hand vertical axis) for the following 12 factors: MRT (market beta); EP (earnings-to-price ratio; SMB (size); HML (book-to-market ratio), MOM (momentum), LIQ (liquidity), DEF (default likelihood), IVOL (idiosyncratic volatility); DCG (durable consumption goods); SRV and LRV (short-run and long-run volatility) and CVOL (consumption volatility). Any t-statistics higher than 4.9 are located at 4.9.
- Via the dashed horizontal black line (and the left-hand vertical axis), the conventional t-statistic criterion for significance (t-statistic=1.96, or p-value=0.05).
- The solid light-blue, the dotted red and the dashed light green lines (using the left-hand vertical axis) show three ways of adjusting the conventional t-statistic criterion to account for aggregate/cumulative data snooping bias. All three lines generally rise with the number of factors tested.
The point of the chart is that many factors found significant in isolation become insignificant, after accounting for luck, in the broader context of all similar published research.
In summary, cumulative exploration of the same financial data by all researchers (including practitioners) for predictive variables/strategies feeds a growing aggregate data snooping bias that requires ever more stringent significance tests.
The paper includes a catalog of discovered factors explaining the cross-section of future U.S. stock returns.
Cautions regarding findings include:
- As noted, the study may exclude some published/pre-published factors and cannot include “invisible” factors, not disseminated because they do not work. Accounting for such failures would increase data snooping bias and indicate even more stringent significance tests.
- The statistical significance testing discussed above generally assumes that stock returns have tame (normal-like) distributions. To the extent that actual variable distributions are wild (for example, fat-tailed), test assumptions and implied predictive powers break down.
- As noted by the authors, factors with strong theoretical bases may deserve leniency in statistical tests.
- In general, stock return factor studies use gross returns, ignoring any trading/shorting costs required to exploit them. Using net returns instead may disrupt findings substantially.
For additional perspective, see “The Significance of Statistical Significance?”, “Snooping Bias Accounting Tools”, “Navigating the Data Snooping Icebergs” and “Effects of Market Adaptation”.